Matz在2016年的Rubykaigi里做了一个关于Ruby3 Typing的分享。
首先简单介绍一下什么是RubyKaigi。
Kaigi就是日语【会議】的罗马字母写法,顾名思义也就是在日本举行的RubyConf。
RubyKaigi在2006年首次举行时的名字就是【日本Rubyカンファレンス】(Japan Ruby Conference),由于容易与Ruby Central混淆,因此在2007年改名为【日本Ruby会議】,直到2011年停办。
2013年大会重开,改名为【RubyKaigi】,并统一使用英语作为大会的官方名称。
今年的RubyKaigi2016在9月8号到10号京都举行。由于近水流台,有不少像Matz这样的Ruby committer参与分享,所以大会含金量非常高。
官网中以及发布了所有视频,希望以后有机会可以亲身去感受下。
大会的首个Topic是Matz的 Ruby3 Typing(油管直通车)

演讲者Matz就不多做介绍了。

官方没有提供在线版的PPT,我把这个日语演讲“翻译”成以下的文字,为了保持文字通顺,稍微加工了一下。
Ruby3 Typing(Matz)
在2010年以来的新语言很多都是静态类型语言(Static Typed Languages),例如TypeScript、Flow、Go、Swift等等。
与之相比,Ruby没有静态类型,又是上世纪90年代语言,所以有些人会说“Ruby is Dead”、“Rails is Dead”。

但技术有时候就像钟摆,有时候偏向一种技术,有时候又偏向另外一种技术,这是常有的事情。例如静态类型与动态类型“之争”。
1970s到1980s左右,从Smalltalk、lisp摆到Java、C++
接下来又从Java摆到Ruby、JavaScript
到最近又从Ruby、JavaScript摆到Swift、Go
那么未来Swift、Go又会摆到哪里去呢?未来Ruby3的类型又会有什么改变呢?
首先我们需要知道什么是Ruby的type?对于动态类型语言来说,Class不是类型。
另外在Ruby其中一个重要的原则就是Duck typing,也就是说对于一个Ruby对象来说,我们不关心她继承关系(inheritance),也不关心她的内部结构(structure),我们只关心她的行为(behaves)。
请看下面String IO的例子。
Ruby版本的日志输出代码片段:
log(STDERR, "error!")
静态类型版本:
log(dst IO, mesg String)
Ruby StringIO版本:
sio = StringIO.new()
log(sio, "error!")
sio.string # => retrieve string
上面的StringIO例子在静态类型的世界行不通,因为StringIO没有与IO有共同的superclass或interface,所以无法通过编译。
Duck typing使我们在开发的时候不需花时间研究各个Class间的关系,大大降低开发者的开发成本,而且扩展起来也更加灵活。
所以我们可以认为,在Ruby的type就是“Duck”。“Duck”不是Java那样的Nominal type,更不是Class,它是一种被期待的行为。

“期待”只是存在于我们的脑子里面,很暧昧的想法,也正因此Ruby的Type可以很灵活,对比用Class来定义Type的方式会有很多限制。

对比Nominal typing,我(Matz)更喜欢Go的Interface,也就是Structural Subtyping这种方式。

在上面的例子中,上面三行定义一个包含Write方法的interface LogDst,下面三行的log函数接受两个参数LogDst和字符串mesg。在这个函数里我们只需要LogDst有Write的行为(方法)就可以了, 它可能是输出到standard IO、String,或者其他什么地方,我们并不需要关心它的内部逻辑。
Structural Subtyping和Duck typing同样保持很好的灵活性,当然我(Matz)还是更喜欢Ruby的Duck Typing :–)。
DRY(Don’t repeat yourself)是Ruby另外一个重要原则。

为了避免不必要的重复,我们不会在程序写实际上不需要的东西,也就是说Ruby程序的运行不依赖于type annotations,因此我们就不需要它们,甚至要去除它们。
但是Dynamic Typing也是存在不少不足的地方。
- 在程序运行时能发现错误

- error message不友好,信息量少,下面可能是我们最熟悉但又“莫名其妙”的错误信息

- 如果测试覆盖不够,可能会有预想不到的typing error
- 缺少文档,像Ruby这样没有类型的语言写程序的时候非常爽,但读程序的时候就可能有困难了,所以有些人会写下面这样的注释

可能会有人吐槽,最终不还是要把类型写出来吗。。。
但。。。无论如何还是不想指定类型,绝对不想。。。(Matz特别强调两次,全场都笑了)

因为这样会降低程序的灵活性,但为了以后的维护,我们又希望有可读性好的文档。
除了把类型信息像刚才那样写在注释外,还有另外一个做法是把他写在文档中。把类型写在文档里,但实际程序又不会做类型检查,到头来实际两边都没有讨好。
至少对Ruby来说Type Annotation,Mixed/Gradual都不是好主意。
正是因为还有以上种种问题,Ruby还有很多改进的空间,

并且我们作为一个工程师应该要主动去解决这些问题。

有些人提出了Static Typing with Type Inference的解决方案,但这个方案还是没能解决静态类型不够灵活的缺点。
又有人提出Gradual Typing 或者 Optinal Typing的解决方案,但这两种类型实际还是静态类型,因此灵活性这个问题还是没能得到解决。
Ruby需要除上面以外其他的什么东西,一种像Static Typing这样进行类型检查,但又像Duck Typing这样灵活的类型。

暂且就把她叫做Soft typing。
Soft typing是一套用行为来定义的Type System。

所谓行为就是一组的方法和参数数量、类型等。

回到刚才日志输出的例子,Go版本的interface其实可以让程序自动生成,并且我们写程序的时候也不需要关心
interface(Type)的名字(取名字对有些人来说是件麻烦事),

因此我们只可以忽略这些细节,专注于程序开发。(Happy Programming的真谛)

例如,我们可以把Type信息搜集起来,就像放到数据库中一样。然后,我看可以从这个数据库中获取Type的定义和Type行为(方法)。
我们也这些Type信息看做是一种表达式(expression),

例如,我们可以检查当把A表达式赋值给B表达式时是否兼容。

我们也可以检查某个类型有没有对应的方法。

这样的做法也许并不能做到100%的类型检查,但还是比之前一点都没用要好。

如果找不到对应的类型信息,由于本来就是dynamic typing,那么我们就退回到dynamic typing就可以了。
有两种方式实现Soft typing。
一个是利用ad-hoc type的信息。
例如,有a表达式(也有可能是变量),我们期望她有gsub,slice,map三个方法,如果找不到有对应的class满足这个条件的,那就抛出错误信息。

但对于在运行时不断动态添加或修改的方法,这种检查方式就无能为力了。
另外一个是在运行时搜集类型信息,

特别是在测试的时候,

一般Libray或者Gem都会进行测试,那么我们可以在测试的同时,建立类型数据库。
这样我们就可以在发布Gem的同时,以某种方式一起创建和发布与之对应的类型数据库。

IDE也可以利用这些Type Database的信息,让我们可以构造更加有效率、聪明的开发环境。
可惜的是在先阶段以上这些暂时都还只是构想,我们还不能用到。

所以让我们一起期待Ruby3吧!

最后,我们(Ruby committees)有一个很重要的信息传递给大家,我们是非常重视开发者的。

我们不会对Dynamic typing的“缺点“视而不见,或者叫开发者多做测试就了事,而是希望努力的改善Ruby,让开发者有更好的开发体验。

关于Ruby3什么时候发布,目前还是不知道。。。

从committee management的角度来看,开源软件一般没有所谓的dead line,也没有很明确的road map,至少对于Ruby这个项目来说没有。但如果什么都没有又很难开展工作,因此我们对Ruby3的开发指定了3个目标。

就像当年美国登月一样,也是先定了一个困难、远大的目标,然后大家一起为之努力,最后成功。
那Ruby3的三个目标什么时候才能实现呢?我(Matz)希望在下一次的日本奥运会的时候。。。
虽然Ruby3还”遥遥无期“,但Ruby前进的脚步是不会停止的。


我们会一直不遗余力的帮助广大开发者在编程中找到乐趣—Happy Hacking!
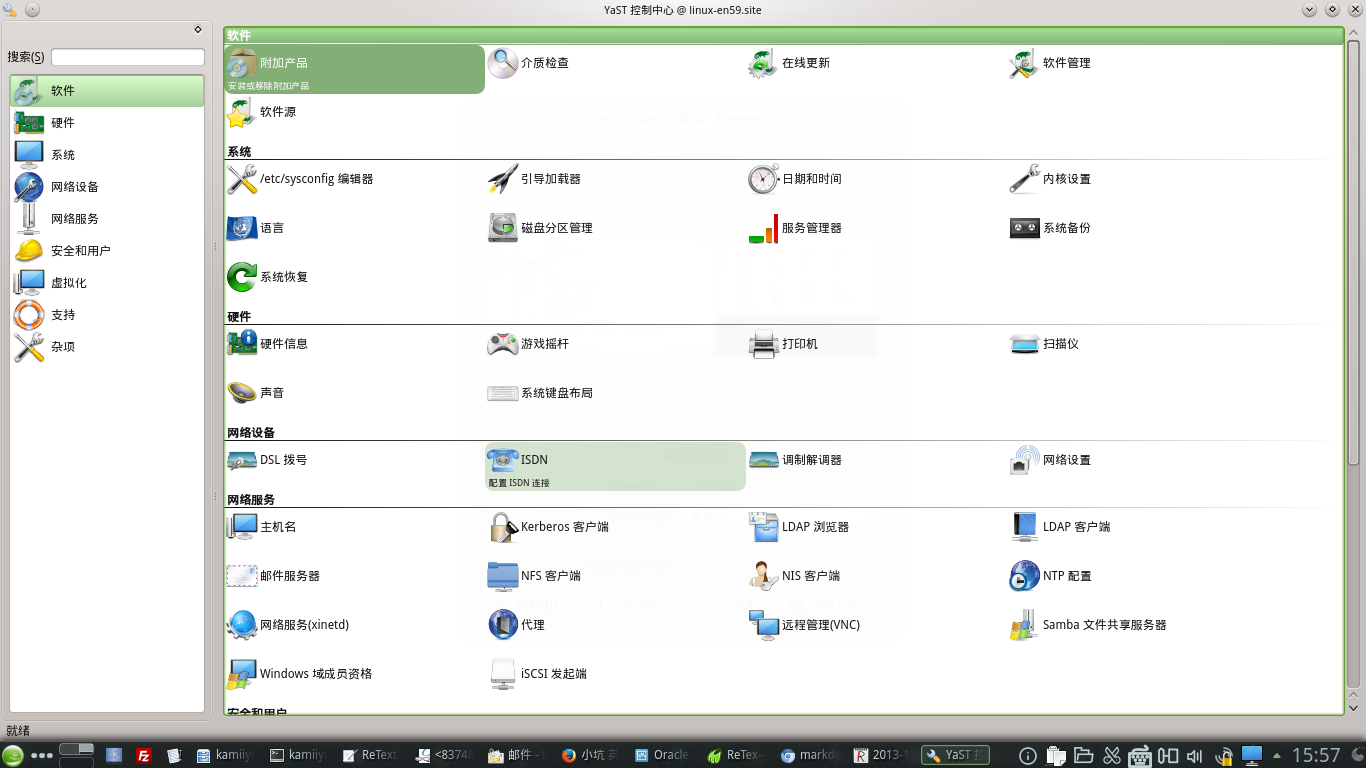 用RVM安裝Ruby後,上圖的所有項目的子窗口都無法再彈出了。試着在命令行用root身份登陸運行
用RVM安裝Ruby後,上圖的所有項目的子窗口都無法再彈出了。試着在命令行用root身份登陸運行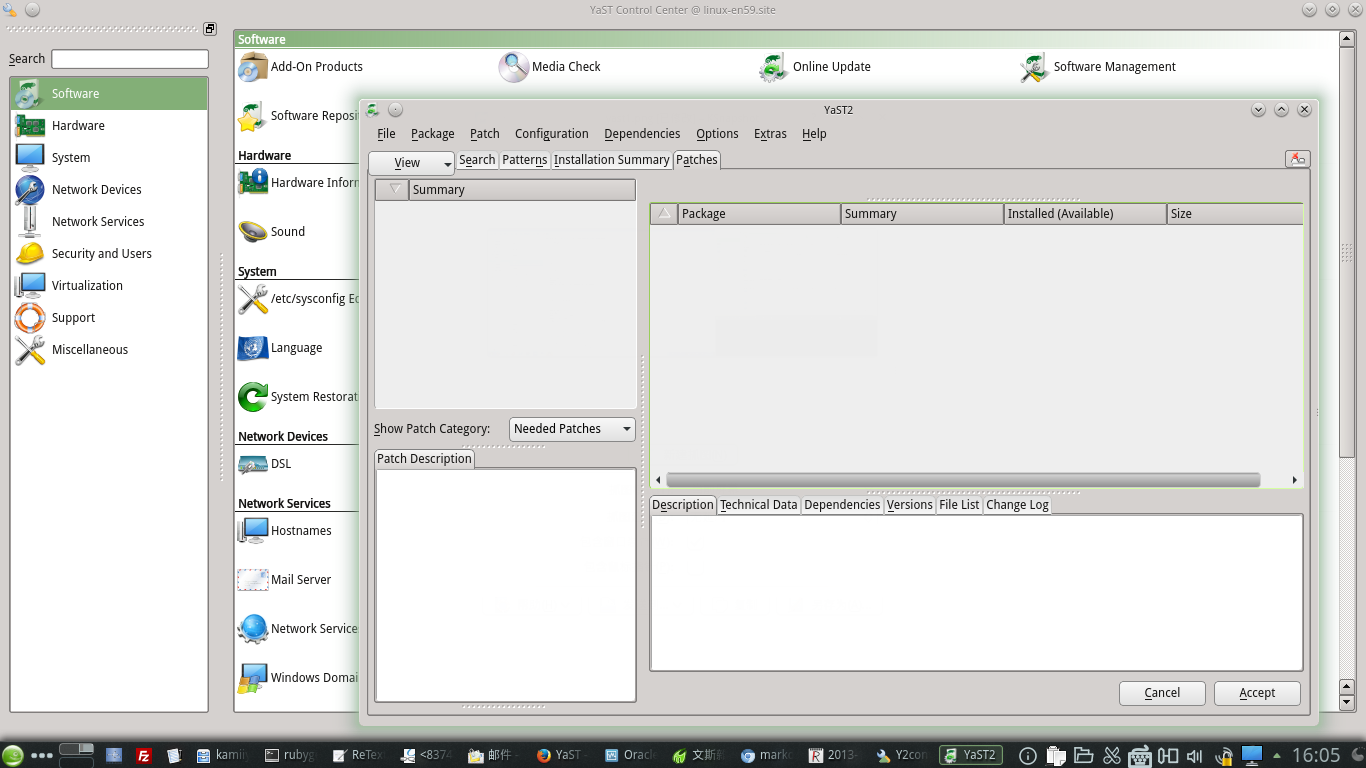 後來差了一下yast的日誌
後來差了一下yast的日誌 原來YaST也用到Ruby!
原來YaST也用到Ruby!
 手術後:
手術後: